サイト全体をWordPressのテーマで構築しつつ、一部のページをスクラッチ(ゼロベース)で作成することが稀にあります。
そのようなページを作成する際、ヘッダーとフッターにはWordPressで使用しているCSSやメニュー内容を活用し、システムを構築します。
しかし、WordPress側でヘッダーやフッターの内容が変更されると、別途作成したページも更新する必要があります。
知識のある担当者や運営側がその修正に対応できれば問題ありませんが、大半の場合、気づかないまま放置されることが多く、その結果、ヘッダーやフッターの内容に不一致が生じることがあります。
この問題を解決するには、WordPress側のヘッダーやフッターの内容を取得し、HTMLへ反映する仕組みを導入することが有効です。
以下に、PHPを使用したその方法の一例をご紹介しますので、参考にしてください。
1.準備
ヘッダー・フッターの取得を実装するためには、いくつかの準備が必要です。以下を確認してください。
<前提条件>
・FTPソフトが使用できること
サーバー上にファイルをアップロードするため、FTPソフトでファイルの作成や編集が行える環境が整っていることが必要です。
・PHPが動作するサーバー
サーバー上でPHPが正常に動作する環境が必要です。
2.ソースコードの取得とヘッダー・フッターの出力
以下のサンプルコードを使用して、WordPressサイトからヘッダーとフッターの内容を取得し、HTMLに出力する方法を示します。
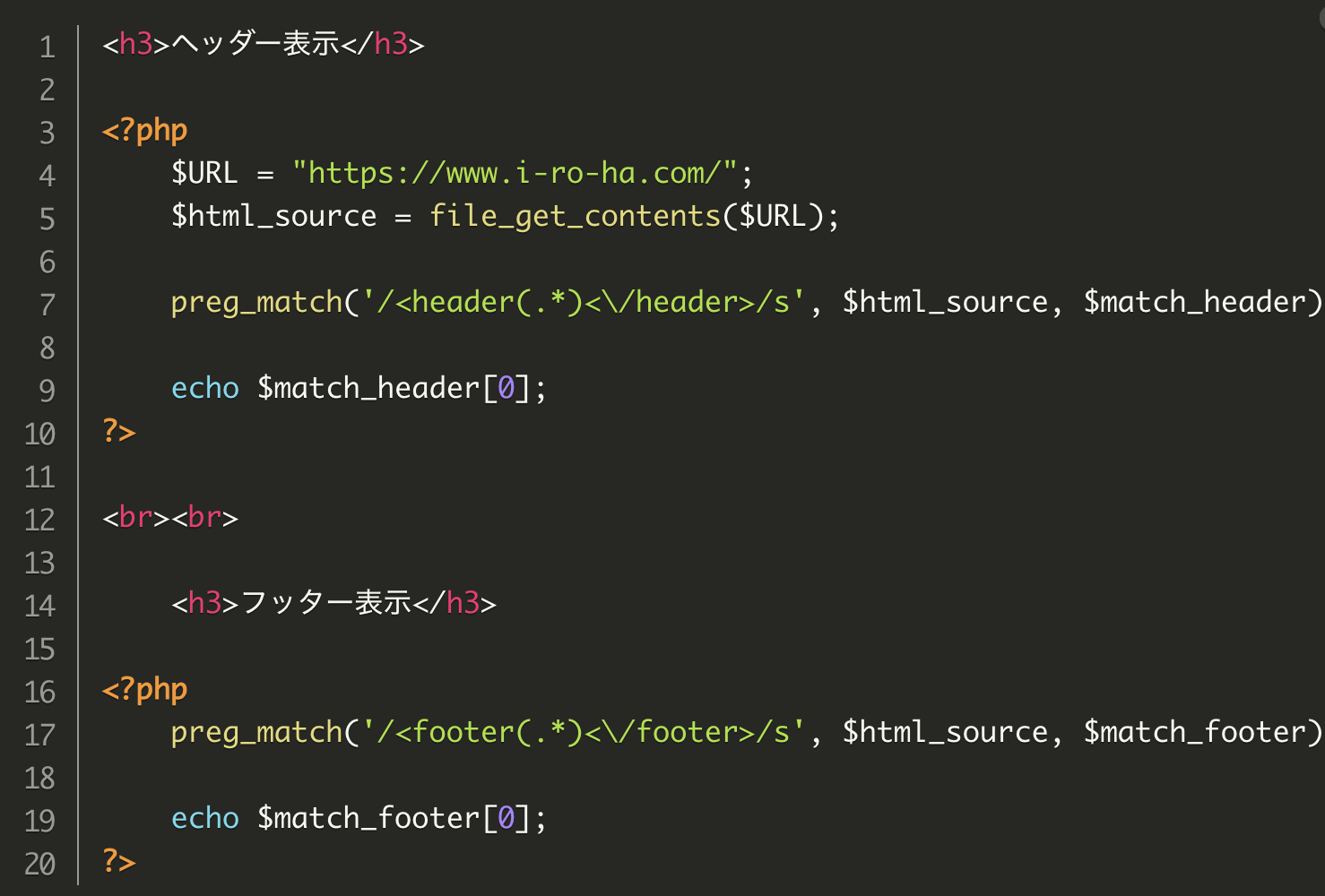
ファイル名: index.php
<h3>ヘッダー表示</h3>
<?php
$URL = "https://www.i-ro-ha.com/";
$html_source = file_get_contents($URL);
preg_match('/<header(.*)<\/header>/s', $html_source, $match_header);
echo $match_header[0];
?>
<br><br>
<h3>フッター表示</h3>
<?php
preg_match('/<footer(.*)<\/footer>/s', $html_source, $match_footer);
echo $match_footer[0];
?>
このコードの仕組み
PHPを使用して指定したURLのHTMLソースコードを取得し、その中から<header>タグと<footer>タグで囲まれた部分を抽出して表示します。
プログラムの仕組み
1.指定URLのHTMLを取得:
$URL = "https://www.i-ro-ha.com/";
$html_source = file_get_contents($URL);
file_get_contents($URL)を使って、指定URLのHTMLソースを取得し、変数$html_sourceに格納します。- この関数は指定URLの内容を文字列として読み込む関数です。
2.正規表現でヘッダー部分を抽出:
preg_match('/<header(.*)<\/header>/s', $html_source, $match_header);
echo $match_header[0];
preg_match()関数を使用して、HTMLソースの中から<header>タグに一致する部分を検索。- 正規表現
/<header(.*)<\/header>/s:<header>から</header>までを対象。s修飾子で改行を含む全ての文字列にマッチ可能。
- マッチした内容を配列
$match_headerに格納。$match_header[0]にマッチした全体の文字列が格納される。
echo $match_header[0];で抽出した<header>部分を表示。
3.正規表現でフッター部分を抽出:
preg_match('/<footer(.*)<\/footer>/s', $html_source, $match_footer);
echo $match_footer[0];
- 同様に、
preg_match()で<footer>タグ部分を検索・抽出。 - 抽出されたフッター部分を
$match_footer[0]として出力。
プログラムの動作手順
- 指定URLのHTMLを取得:
- 指定されたURL(
https://www.i-ro-ha.com/)のHTMLソースコードを取得。
- 指定されたURL(
- ヘッダー部分を解析・表示:
- HTMLの中から
<header>タグ部分を検索。 - 抽出して表示。
- HTMLの中から
- フッター部分を解析・表示:
- HTMLの中から
<footer>タグ部分を検索。 - 抽出して表示。
- HTMLの中から
使用技術
- PHPの基本関数:
file_get_contents(): URLの内容を取得。preg_match(): 正規表現でパターンマッチング。
- 正規表現:
/.../s: 正規表現のパターン。s修飾子で改行を含むマッチングを許可。<header(.*)<\/header>:<header>から</header>までの全ての文字列を対象。
<footer(.*)<\/footer>:<footer>から</footer>までの全ての文字列を対象。
注意点
- 外部サイトへの依存:
- 指定URL(
https://www.i-ro-ha.com/)が応答しない場合、HTMLソースを取得できないため、動作しません。
- 指定URL(
- 正規表現の信頼性:
- 正規表現ではHTMLの構造が複雑な場合やネストされたタグに対応しづらい。
- 高度なHTML解析には、PHPのDOMライブラリを使用する方が推奨されます。
- セキュリティ:
file_get_contents()で外部ソースを取得する際、予期しないデータが含まれる可能性があるため、適切なサニタイズ処理が必要。
デモ
デモの不具合や質問等の連絡はお問い合わせページからお願いします。



{kind=link}